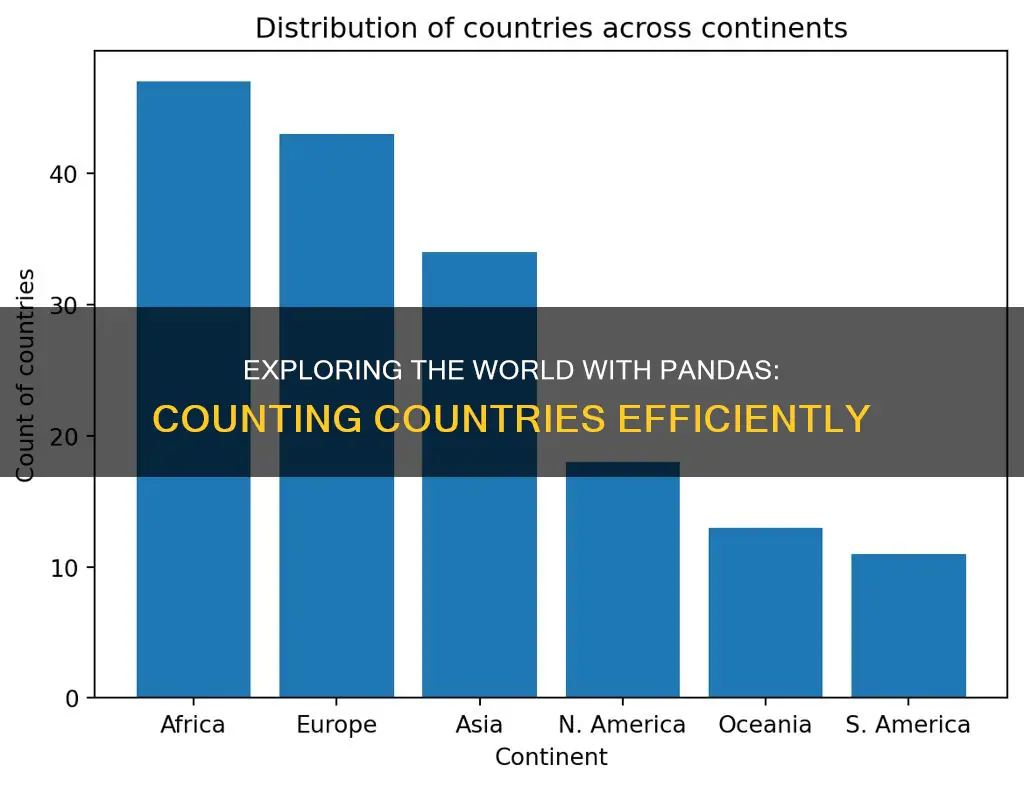
Pandas is a powerful tool for managing and analyzing data in Python, especially when dealing with two-dimensional data tables. One common task is counting the occurrences of countries within a dataset, which can be achieved using various methods such as groupby functions or iterating over rows. For example, if you have a dataset containing Netflix releases with countries of production, you can use groupby and cumsum to visualize how the running total for each country changes over time. Alternatively, you can use the count function to get the total number of countries in a column.
| Characteristics | Values |
|---|---|
| Data structure | Two-dimensional data tables in Python |
| Dataframe preview | First 5 rows or last 5 rows |
| Dataframe columns | Country, year, pop, continent, lifeExp, gdpPercap |
| Grouping data | Groupby function on the continents and count the capitals within each |
| Counting countries | df['ship_to_countries'].str.count(',').add(1).groupby(df.ship_to_countries).sum() |
Explore related products






What You'll Learn
![]()
Counting countries in a pandas dataframe
Step 1: Importing the Required Libraries
First, ensure that you have the necessary libraries installed. The pandas library is essential for data manipulation and analysis. You can install it using the following command:
Python
Pip install pandas
Once installed, import the library into your Python script:
Python
Import pandas as pd
Step 2: Reading the Data
To count countries in a pandas dataframe, you'll need to read your data into a dataframe. Typically, country data is stored in a CSV file or a similar tabular format. Use the `pd.read_csv()` function to read the data into a dataframe. For example:
Python
Replace 'filename.csv' with the path to your file
Df = pd.read_csv('filename.csv')
Step 3: Understanding the Data Structure
Before proceeding with counting countries, it's crucial to understand the structure of your data. Use the head() and tail() functions to preview the first few and last few rows of your dataframe:
Python
Preview the first 5 rows
Df.head()
Preview the last 5 rows
Df.tail()
Examine the columns in your dataframe and identify the ones relevant to countries, such as country names, regions, or continents.
Step 4: Counting Countries
Now, let's get to the core of the task—counting countries. Depending on your data structure, you can use different approaches:
Method 1: Grouping by Continent or Region
If your dataframe includes columns for continents or regions, you can group the data by these categories and then count the countries within each group. Here's an example:
Python
Grouping by continent and counting countries
Country_count = df.groupby('Continent')['Country'].nunique()
This code groups the dataframe by the 'Continent' column and then counts the unique country names in the 'Country' column within each group.
Method 2: Counting Comma-Separated Countries
If your data includes comma-separated country names in a single column, you can use the `str.count()` function to count them:
Python
Counting comma-separated countries
Df['country_count'] = df['ship_to_countries'].str.count(',') + 1
This code assumes that the country names are separated by commas in the 'ship_to_countries' column and calculates the count of countries in each row.
Method 3: Filtering and Extracting Country Data
In some cases, you may want to count countries based on specific criteria, such as population or area. You can use the pandas dataframe filtering capabilities to achieve this. Here's an example:
Python
Filtering and extracting big countries based on area
Def big_countries(world_df):
Big_countries_df = world_df[world_df['area'] >= 3000000]
Return big_countries_df
Calling the function with a sample dataframe
Result = big_countries(world_df)
This code defines a function `big_countries` that takes a dataframe as input and filters the rows to include only countries with an area greater than or equal to 3,000,000 square kilometers.
Step 5: Analyzing the Results
After applying the appropriate counting method, you can analyze the results. Depending on your specific analysis goals, you might want to print the country counts, visualize them, or perform further calculations.
Remember that the exact steps and methods may vary depending on your data structure and requirements. Ensure that you understand your data thoroughly before proceeding with any analysis.
Magnets and Nickle-Lined Copper Pans: Attraction or Repulsion?
You may want to see also
Explore related products






![]()
Grouping by country and date
Grouping data by country and date is a common task in data analysis, and pandas provide a powerful tool to accomplish this. Here is a step-by-step guide on how to achieve this:
Reading the Data
First, you need to read the data into a pandas DataFrame. Assuming your data is in a CSV file, you can use the `pd.read_csv()` function to read it into a DataFrame. Make sure to specify the file path and the delimiter used in your file. For example:
Python
Import pandas as pd
Replace 'filename.csv' with the actual file path
Df = pd.read_csv('filename.csv')
Exploring the Data
Before proceeding, it's a good idea to explore your data to understand its structure and content. You can use the head() function to preview the first few rows of the DataFrame:
Python
Df.head()
This will display the columns and the first few rows of your data, helping you identify the column names and data types.
Now, let's get to the main task of grouping the data by country and date. Pandas provide the `groupby()` function, which allows you to group the data based on one or more columns. In this case, you want to group by both the "Country" and "Date" columns. Here's how you can do it:
Python
Grouped_data = df.groupby(['Country', 'Date'])
In the code above, we pass a list of columns, `['Country', 'Date']`, to the `groupby()` function. This tells pandas to group the data by unique combinations of country and date.
Aggregating the Data
After grouping the data, you might want to perform aggregation operations on other columns within each group. For example, you might want to calculate the sum, mean, or count of a specific column within each country and date group. Let's assume you want to calculate the average of a column named "Value" within each group:
Python
Average_values = grouped_data ['Value'].mean()
In this code, `['Value']` selects the "Value" column from the grouped data, and the `mean()` function calculates the average value within each group.
Resetting the Index
After performing your aggregations, you might want to reset the index of the resulting DataFrame to make it easier to work with. You can do this using the `reset_index()` function:
Python
Final_result = average_values.reset_index()
Displaying the Results
Finally, you can display the results to see the average values for each country and date:
Python
Print(final_result)
This will print the DataFrame with the country, date, and the corresponding average values.
By following these steps, you can effectively group your data by country and date, perform aggregations, and gain valuable insights from your data. Pandas provide a versatile toolkit for data manipulation and analysis, making it easier to extract meaningful information from your datasets.
Clearing AC Drain Pan Blockages: DIY Guide
You may want to see also
Explore related products






![]()
Using a groupby function
To count countries in pandas using a groupby function, you can follow these steps:
Understanding the Data
Firstly, you need to understand the structure of your data. In this case, you are working with a dataset containing information about countries, and you want to count the number of countries in each continent. The relevant columns in your DataFrame are 'Country' and 'Continent'.
Grouping the Data
The groupby function in pandas is used to group data based on values in one or more columns. In this case, you want to group the data by the 'Continent' column. The basic syntax for grouping data by a single column is as follows:
Python
Df.groupby('Continent')
This will return a GroupBy object that you can use for further operations.
Aggregating the Data
Once you have the GroupBy object, you can apply various aggregation functions to summarise and analyse the data. In this case, you want to count the number of countries in each continent. The count() function is used to count the number of non-null values in each group. Here's how you can use it:
Python
Df.groupby('Continent')['Country'].count()
This code will count the number of countries in each continent by grouping the data by the 'Continent' column and then counting the number of non-null values in the 'Country' column for each group.
Visualising the Results
After applying the groupby and count operations, you will get a Series object with the continent names as the index and the corresponding count of countries as the values. For example:
Europe 4
North America 2
This output shows that there are 4 countries in Europe and 2 countries in North America in your dataset.
Combining with Other Functions
The groupby function can also be combined with other pandas functions to perform more complex analyses. For example, you can use the agg() function to apply multiple aggregation functions at once. Here's an example:
Python
Df.groupby('Continent')['PopulationEst'].agg(['size', 'sum', 'mean', 'std'])
This code calculates the size (number of countries), sum, mean, and standard deviation of the 'PopulationEst' column for each continent.
By utilising the groupby function in pandas, you can efficiently count countries in different continents and gain valuable insights from your data.
Duke E101E: What Pan Size Fits?
You may want to see also
Explore related products






![]()
Summing populations by country
Python
Import pandas as pd
Sample data
Data = {'Country': ['Country_A', 'Country_B', 'Country_A', 'Country_C'],
'Population': [1000, 1500, 500, 2000]}
Df = pd.DataFrame(data)
Grouping data by country and summing populations
Country_populations = df.groupby('Country')['Population'].sum()
Print(country_populations)
In this example, the groupby function is used to group the data by the 'Country' column and then sum the 'Population' column for each unique country. The result will be a Series with country names as the index and the summed populations as the values.
You can also use the aggregate function (agg) along with groupby to achieve the same result. This allows you to specify multiple aggregation functions at once. For example:
Python
Sample data
Data = {'Country': ['Country_A', 'Country_B', 'Country_A', 'Country_C'],
'Population': [1000, 1500, 500, 2000],
'Cases': [10, 5, 2, 8]}
Df = pd.DataFrame(data)
Grouping data by country and summing populations and cases
Df_grouped = df.groupby('Country').agg({'Population': 'sum', 'Cases': 'sum'})
Print(df_grouped)
In this example, the groupby function is used to group the data by country, and the aggregate function is used to sum the 'Population' and 'Cases' columns for each unique country. The result will be a DataFrame with country names as the index and the summed populations and cases as the columns.
Additionally, when visualizing population data, you can create bar charts using the matplotlib library. Here is an example:
Python
Import pandas as pd
Import matplotlib.pyplot as plt
Sample data
Data = {'Country': ['Country_A', 'Country_B', 'Country_C'],
'Population': [1000, 1500, 2000]}
Df = pd.DataFrame(data)
Grouping data by country and summing populations
Country_populations = df.groupby('Country')['Population'].sum()
Creating a bar chart
Plt.bar(country_populations.index, country_populations.values)
Plt.xlabel('Country')
Plt.ylabel('Population')
Plt.title('Country Populations')
Plt.show()
In this example, the groupby function is used to sum the populations by country, and then a bar chart is created using matplotlib, with country names on the x-axis and populations on the y-axis.
By utilizing these techniques, you can effectively sum populations by country in Pandas and create visualizations to better understand and present the data.
Slow-Cooked Comfort: The Perfect Hot Chocolate Crock-Pot Timing
You may want to see also
Explore related products






![]()
Counting unique countries
Now, select the column in which you want to count the unique values. For this example, let's assume the column name is "Country". To find the unique countries, you can use the unique() function provided by pandas:
Python
Unique_countries = df['Country'].unique()
This will give you a list of unique countries in the "Country" column. To get the count of unique countries, you can use the len() function:
Python
Num_unique_countries = len(unique_countries)
Alternatively, you can use the nunique() method, which stands for "number of unique values". This method tells you how many distinct entries exist in a column:
Python
Num_unique_countries = df['Country'].nunique()
If you want to count unique values within specific groups, you can use the groupby() method combined with nunique():
Python
Unique_countries_by_group = df.groupby('Group')['Country'].nunique()
This will provide you with the number of unique countries within each group.
Additionally, if you want to know how many times each unique country appears in the column, you can use the value_counts() method:
Python
Country_counts = df['Country'].value_counts()
This will give you a series with each country and the number of times it occurs in the dataframe.
By utilizing these methods, you can effectively count unique countries and gain insights into the distribution and frequency of country data in your Pandas dataframe.
Pano and Fever in Dogs: What's the Link?
You may want to see also
Frequently asked questions
You can use the following code: `df['ship_to_countries'].str.count(',').add(1).groupby(df['ship_to_countries']).sum()`.
You can use the groupby function to group by the continent and then count the number of countries in each group.
You can use the following code: pd.crosstab(df['Year'], df['Country']).plot.line()`.































